Engineering
The Local-First Software Movement: Building Web Apps That Run Directly on the User's Device
A practical engineering breakdown of local-first architecture, synchronization trade-offs, and privacy boundaries in modern web apps.
The Local-First Software Movement: Building Web Apps That Run Directly on the User's Device
A practical engineering breakdown of local-first architecture, synchronization trade-offs, and privacy boundaries in modern web apps.
Building local-first web applications for speed and privacy is not a branding idea. It is a direct response to how cloud-first UX feels in real use.
Most teams know this pain already. A user clicks something simple and waits for a network round trip. Then they click again and wait again. Each wait is small, but the app still feels heavy.
The same pattern shows up in file workflows. A user uploads a payload, waits for inspection, gets an error, adjusts the file, and uploads again. The compute may be fast on the server, but the workflow still loses time to transport.
We got used to this because cloud architecture solved many hard deployment problems. Centralized state made sync and control easier. The trade-off was interaction speed and, in many cases, data ownership.
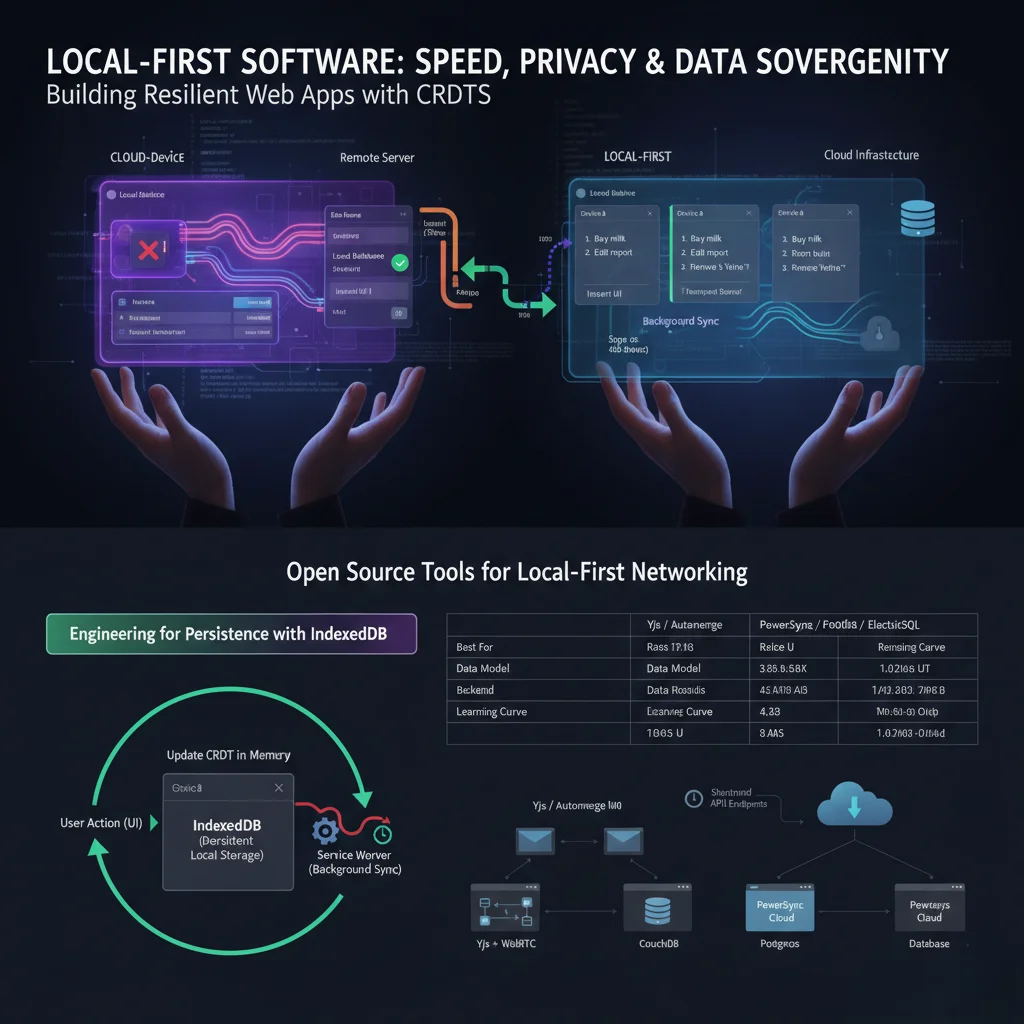
Local-first turns that trade-off around. You write to local state first. The UI updates immediately. Synchronization happens in the background. When the browser is the execution layer, inspection, transformation, and validation can happen near the selected data instead of behind a remote request.
The immediate change is simple: the product feels faster, and work does not stop just because the network drops. It also changes something teams should care about more than they usually do. The user keeps more primary control of their data.
Cloud-First Bottlenecks in Daily Use
A cloud-first web app is usually a remote database with a browser UI on top.
The typical action path is familiar. The user triggers a write, the browser calls an API, the server validates and persists, the browser receives a response, and only then does the UI settle.
Even in a healthy system, this path has friction:
- Network latency stacks across many interactions
- Intermittent connections break write flows
- Spinners become normal UX
- Retries and race conditions leak into frontend code
- Upload and download costs become part of basic tool behavior
A lot of teams hide this with optimistic UI. That works up to a point. But optimistic code also adds complexity because the UI is pretending a local commit happened, while the source of truth is still remote.
You end up writing recovery logic for the case where the optimistic write fails. Then conflict handling. Then reconciliation on refresh. It works, but the complexity tax grows.
The user-facing failure is usually simpler. The app looks busy, the save status feels uncertain, and reconnect recovery becomes part of the product experience.
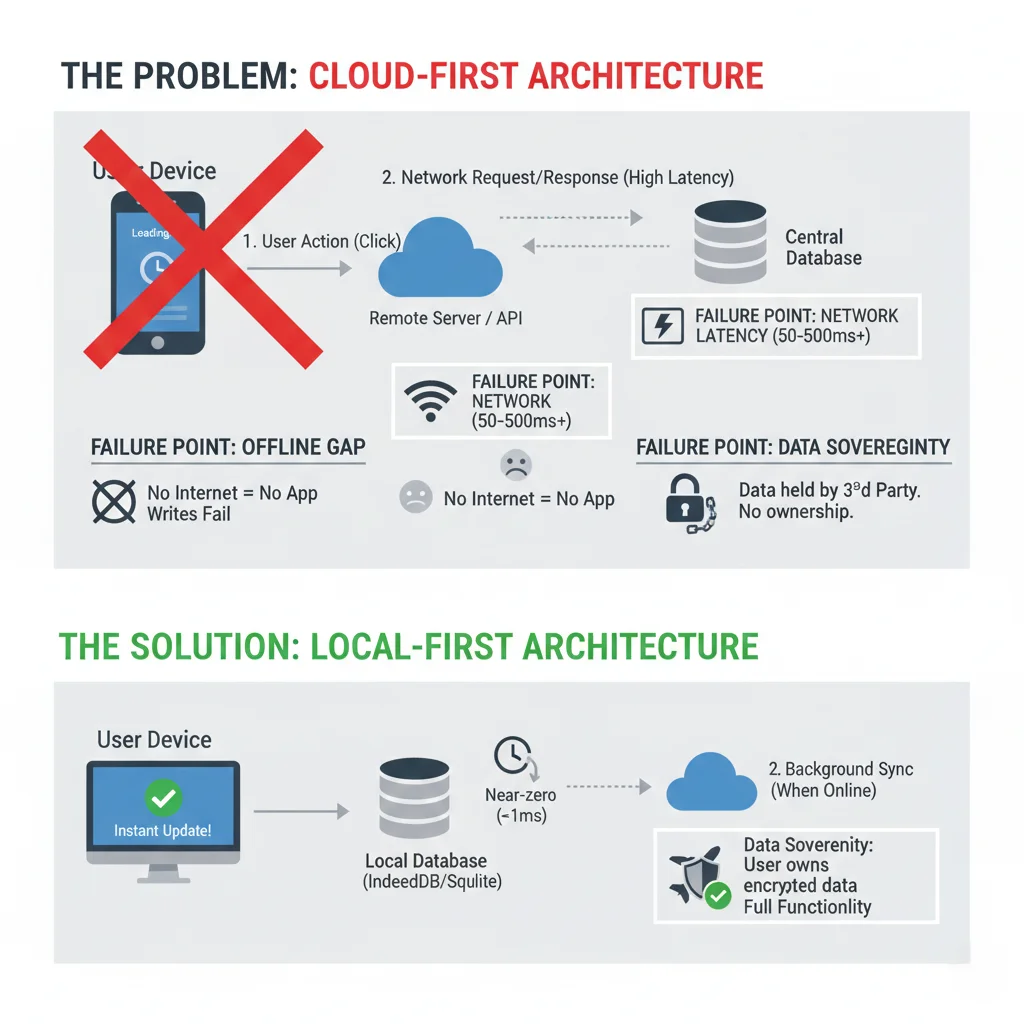
What Local-First Actually Changes
Local-first does not mean no server. It means the local replica is primary for interaction.
In practice, reads come from local storage, writes commit locally first, sync pushes operations out of band, and remote peers converge later. The shape is still distributed, but the interaction path is no longer waiting on the remote database for every basic action.
That gives you latency compensation by architecture, not by animation tricks. When a local write is a function call against IndexedDB, OPFS-backed storage, or SQLite in WASM, the UI can respond immediately.
This is why people describe local-first apps as feeling "native." The core action path does not wait on distance. In browser-native tools, that same placement decision can keep file reads, metadata inspection, and deterministic transforms inside the tab.
The infrastructure is not one API. IndexedDB, OPFS, File APIs, Streams, Web Workers, WebAssembly, ArrayBuffers, and transferable objects all become parts of the local execution path. The design question is how much work should run before the network becomes involved.
The Hard Part: Synchronization and Conflicts
Once every device can write independently, you need deterministic merge behavior. This is where distributed systems concerns enter frontend work.
If two users edit related fields while offline, you need both sides to converge later without manual conflict prompts every time.
That is where CRDT-based models are useful.
Conflict-free replicated data types are built so independent replicas can merge to the same state, regardless of operation order, as long as each operation eventually arrives.
This is not magic. It is data structure design plus deterministic merge rules.

A Small CRDT Example
A Last-Write-Wins element set is a simple way to understand the merge idea.
class LWWSet {
addSet = new Map<string, number>()
removeSet = new Map<string, number>()
add(element: string) {
this.addSet.set(element, Date.now())
}
remove(element: string) {
this.removeSet.set(element, Date.now())
}
get value() {
const result: string[] = []
for (const [element, addTime] of this.addSet) {
const removeTime = this.removeSet.get(element) ?? 0
if (addTime > removeTime) result.push(element)
}
return result
}
merge(other: LWWSet) {
for (const [el, time] of other.addSet) {
const current = this.addSet.get(el) ?? 0
if (time > current) this.addSet.set(el, time)
}
for (const [el, time] of other.removeSet) {
const current = this.removeSet.get(el) ?? 0
if (time > current) this.removeSet.set(el, time)
}
}
}
This toy model is not enough for every domain, but it explains the core shift. You sync operations, not full authoritative snapshots from one server instance.

Cloud API vs Local-First Sync
Here is how these models usually differ in real products:
| Factor | Cloud-First API | Local-First Sync |
|---|---|---|
| Primary data copy | Remote database | User device |
| Interaction latency | Network dependent | Local storage dependent |
| Offline write support | Often partial | Built into core model |
| Conflict resolution | Server rules or locks | Deterministic merge rules |
| Privacy exposure | Centralized by default | Lower by default |
| Frontend complexity | Heavy optimistic logic | Heavy sync logic |
The trade-off is simple to state. Cloud-first pushes complexity to UI latency handling. Local-first pushes complexity to synchronization and replication design.
That trade-off changes workflow economics. Cloud-first pays a transport cost on the hot path. Local-first pays an engineering cost in storage, merge behavior, and recovery rules.
Latency Compensation Without UI Tricks
In local-first systems, latency compensation is not a UX layer. It is part of storage architecture.
You commit locally first. The user sees the result now, not after a round trip.
This usually removes the visible annoyances users notice first: loading spinners for basic writes, frequent "save failed" interruptions, API retry noise, and repeated payload transfers for deterministic local checks.
For teams, this means less time spent building visual workarounds for network delay, and more time spent on actual product behavior.
Browser storage is now good enough for many workloads. IndexedDB covers durable key-value and document storage, Origin Private File System supports higher-throughput file-like access, and SQLite in WASM can handle relational queries inside the client.
None of these erase sync complexity. They do remove network dependency from the hot interaction path.
They also create new frontend responsibilities. Large dataset bootstrapping needs staged hydration. Heavy transforms need worker offloading. Mobile browsers need memory-aware processing or a tab can freeze during the exact operation meant to feel local.
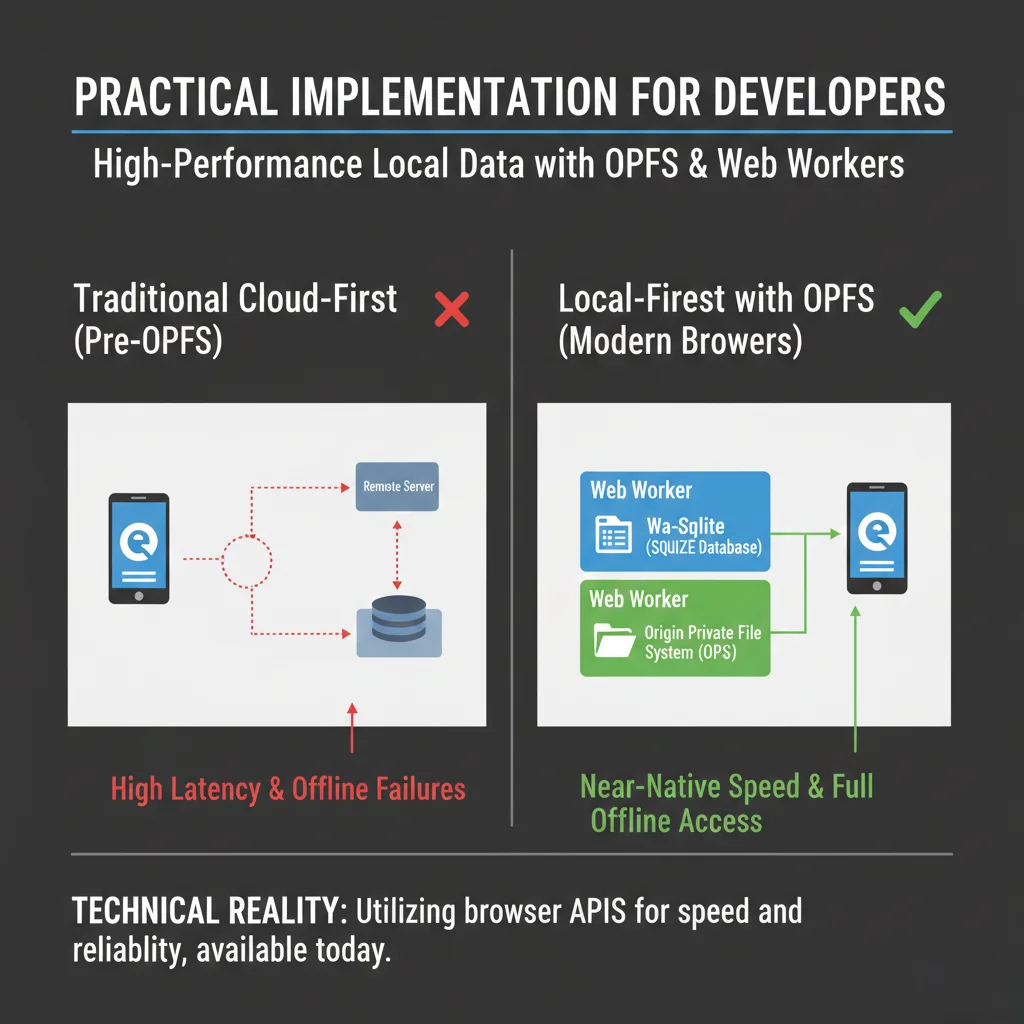
Privacy and Data Sovereignty by Design
Local-first can improve privacy posture because plaintext does not need to leave the device for every operation.
When local-first is paired with end-to-end encryption, the server can relay encrypted operations and store blobs it cannot read while user keys remain client-side.
That model gives you stronger technical guarantees than policy text alone.
In cloud-first systems, privacy is often "trust us." In client-primary systems with strong crypto boundaries, privacy can move closer to "cannot read by design."
This matters for any product handling sensitive notes, internal ops data, or regulated workflows.
It also matters for browser-local audit workflows. Public key inspection, metadata validation, payload diagnostics, and image preparation are often deterministic checks. If the browser can complete the check locally, the workflow gains privacy and avoids the round trip at the same time.
Real Trade-Offs Engineers Hit
Local-first is not free. Teams should go in with clear expectations.
1. Storage Constraints
Browsers have quotas. Modern quotas are better than before, but still finite. You cannot blindly cache everything forever.
The storage strategy has to be explicit. Some data stays local, some data is evictable, and some data should be streamed on demand instead of kept in memory.
This becomes visible when a tool handles large images, archives, or log files. Local-first does not mean load everything into memory. It means decide what should be stored, streamed, transformed, or discarded.
2. First Sync Cost
Initial device bootstrap can be expensive for large datasets. If you dump the whole history at once, first-run experience will suffer.
You need staged hydration and good sync chunking.
The first launch is where many local-first systems lose trust. If hydration blocks interaction, the app feels cloud-slow with extra complexity. The better path is to make the usable subset available first, then continue sync work in the background.
3. Schema Migrations in the Wild
Migrating one central database is controlled. Migrating thousands of local replicas with unpredictable client versions is harder.
You need migration plans that survive delayed updates and partial sync states.
4. History Growth
CRDT and operation logs can grow indefinitely without compaction and pruning strategies.
Garbage collection policy is part of product architecture, not an afterthought.
This extends beyond storage. Large histories can slow startup, increase memory pressure, and make reconnect recovery feel unpredictable.
5. Security Model Complexity
Authorization and validation still matter. If the server only sees encrypted ops, you still need robust permission design and replay protection at the sync layer.
When Local-First Is Not Ideal
Local-first is not a fit for every product. Some systems depend on a single shared source of truth or tight server control, and local replicas add risk. Cases that often need a server-first model include these.
- Large distributed databases with strict centralized consistency
- Real-time multiplayer systems with authoritative state
- Global collaboration tools that require hard real-time conflict rules
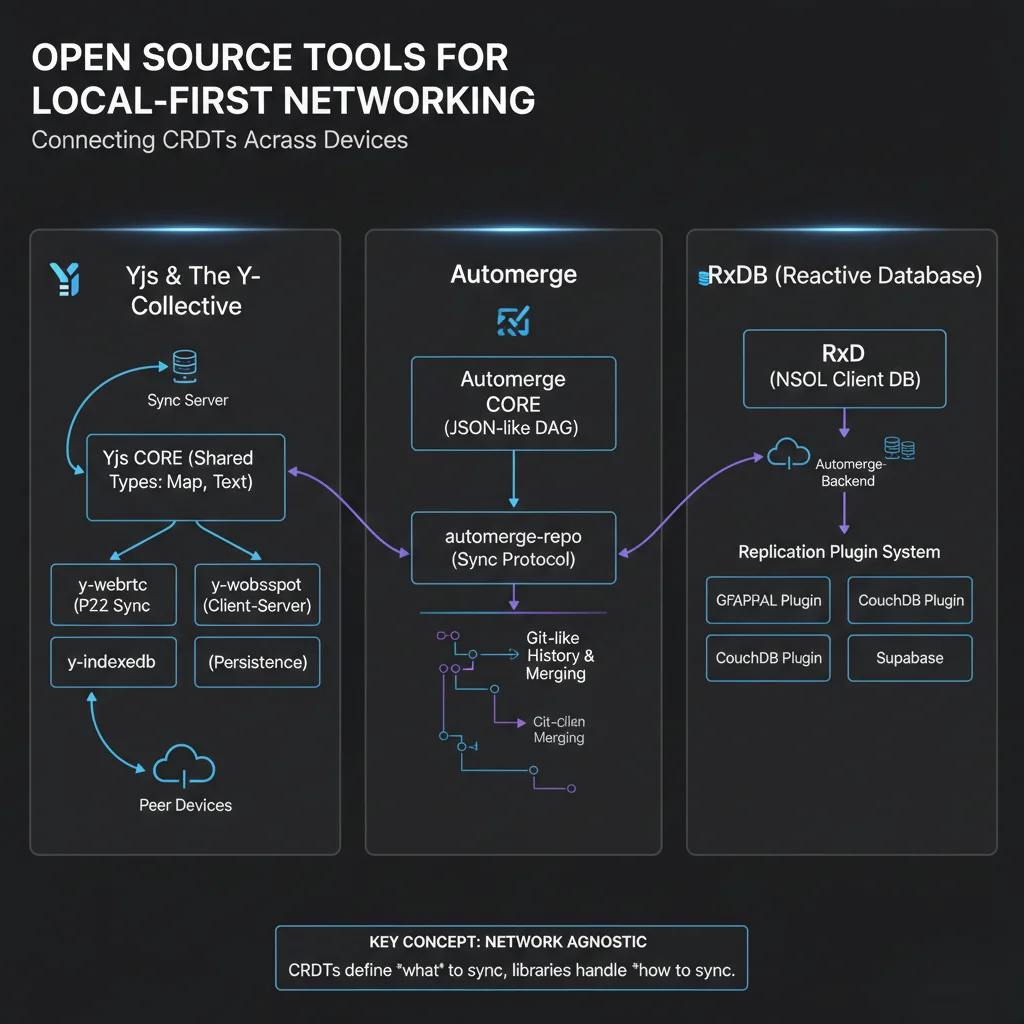
Libraries and Sync Engines Worth Knowing
You do not need to build every piece from scratch.
Common options teams evaluate:
- Yjs for collaboration-focused shared structures
- Automerge for operation-centric CRDT documents
- RxDB for client database workflows with replication plugins
- PowerSync or ElectricSQL style approaches for SQL-centric sync models
The right choice depends on your data model and backend constraints.
If your app is mostly rich text collaboration, your needs are different from an app with relational query requirements and strict audit trails.
Real World Example at SHRTX
Many SHRTX tools are local-first in a narrower but important sense. They do not run distributed CRDT sync, but they do place deterministic work inside the browser when the input is already local to the user.
Image processing, metadata extraction, and payload diagnostics are good examples. Image Compressor, Image Resizer, Image Metadata Viewer, and EXIF Metadata Stripper avoid upload loops for assets that can be inspected or transformed locally. File Size Analyzer follows the same principle for upload planning: inspect the payload before paying the transfer cost.
SHRTX is not a CRDT engine, and it should not pretend to be one. But local-first teams still need supporting utilities in daily work.
That support work is practical and sometimes unglamorous. Teams normalize relay and callback URLs with URL Normalizer, inspect deep links with URL Parser & Debugger, trace redirect behavior with Redirect Chain Tracer, verify payload integrity with Hash Generator and File Hash Batcher, validate sync payload contracts with JSON Schema Validator, and inspect public key structure locally with PGP Key Viewer. These are small checks, but they reduce friction around sync infrastructure and environment hygiene.
Verifying the Technical Claims
Skepticism is healthy here. Local-first does have hype around it.
Still, the core claims are grounded. Network latency is real and measurable. Local writes are faster than remote round trips. Distributed sync complexity is hard, but not mysterious. Deterministic merge models can reduce user-visible conflicts when the data model is designed for them.

The right way to evaluate local-first is not by trend posts. Measure your own interaction paths:
- Time to interactive write
- Failure rate during intermittent connectivity
- User-visible blocking states
- Recovery behavior after reconnect
- Payload transfer avoided by local validation
- Memory behavior during large local processing
If cloud-first already performs well for your domain, keep it. If your app feels slow because every action waits on network, local-first is worth serious consideration.
Practical Closing Insight
Building local-first web applications for speed and privacy is a product architecture choice, not a framework preference.
If your app is interaction-heavy, write-heavy, or built around deterministic local inputs, this model can remove a lot of user friction. It can also improve privacy boundaries when implemented carefully.
You still pay for that with sync and distributed systems complexity. That is the trade.
For many modern web products, it is a trade worth making. The useful question is not whether local-first sounds cleaner. It is whether moving the hot path into the browser makes the workflow more reliable, more responsive, and easier to recover when the network stops cooperating.
Tools Referenced By Topic
Related Reading
Jan 16, 2026 • 10 min
Scaling Browser Utility Suites Without Server Costs
A practical engineering guide to scaling browser-native utility suites with client-side processing, static deployment, local-first workflows, and lightweight infrastructure boundaries.
Mar 14, 2026 • 9 min
Leveraging Modern Web APIs for Desktop-Class Tools
Modern Web APIs let browser tools handle files, compute, and graphics with local speed and clear permissions, without installs.
Feb 3, 2026 • 11 min
Technical Debt in Large Browser Tool Suites
A practical engineering guide to managing technical debt in large browser utility suites with shared registries, validation systems, content governance, and modular tool architecture.