Engineering
Technical Debt in Large Browser Tool Suites
A practical engineering guide to managing technical debt in large browser utility suites with shared registries, validation systems, content governance, and modular tool architecture.
Technical Debt in Large Browser Tool Suites
A practical engineering guide to managing technical debt in large browser utility suites with shared registries, validation systems, content governance, and modular tool architecture.
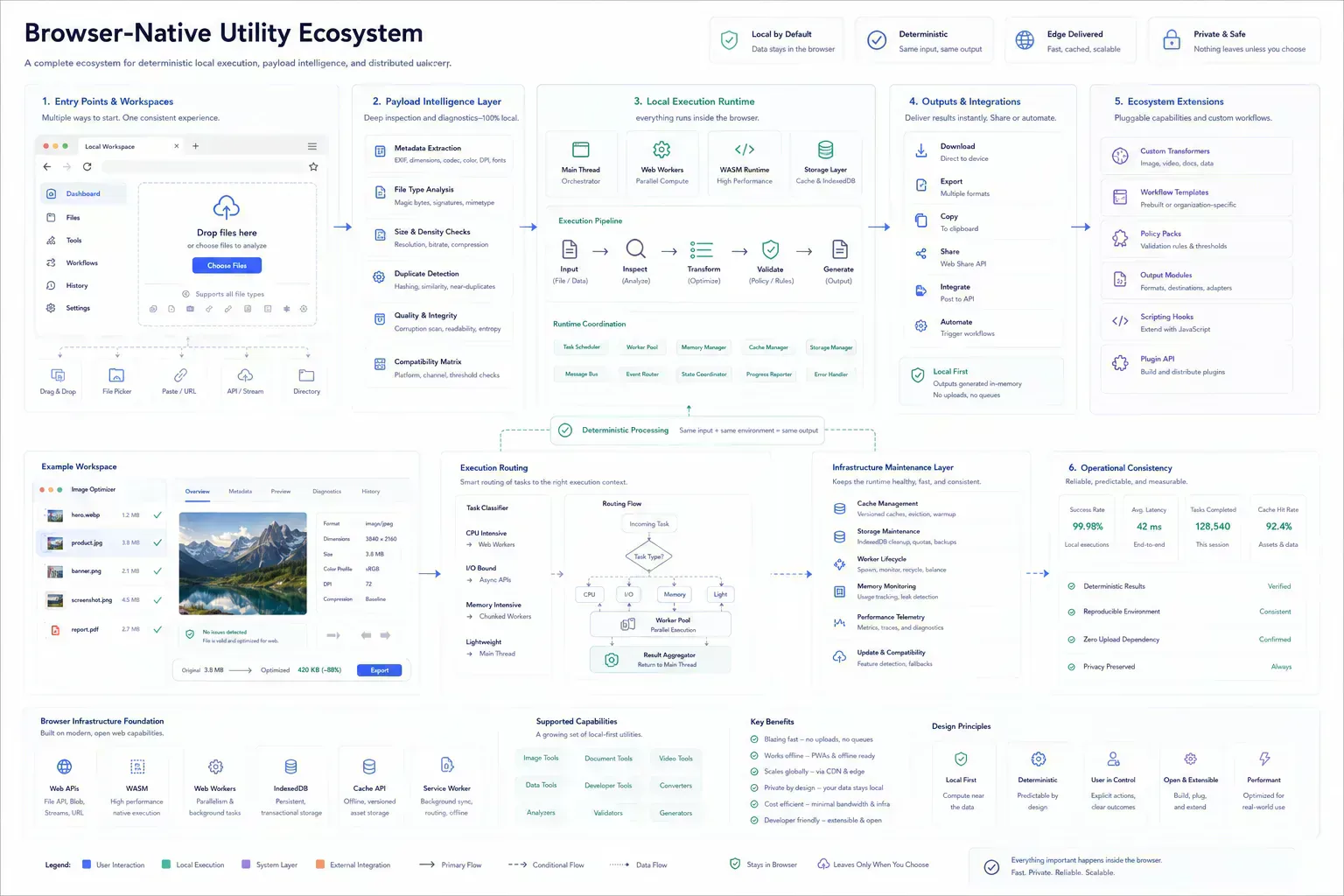
Technical debt in a tool suite rarely announces itself as a broken page. It shows up as a registry entry with the wrong slug, a tool that bypasses the shared renderer, a schema image that no longer matches metadata, or a content page that says the same thing as twenty others.
At small scale, those issues feel like cleanup. At suite scale, they become product behavior. Hundreds of independent tools need enough shared contracts to remain searchable, maintainable, and safe to upgrade.
In browser-native suites, the debt is also runtime debt. One tool assumes local processing, another assumes upload-first behavior, a third keeps object URLs alive too long, and a fourth handles cancellation differently. The work spans code quality, architecture, content governance, metadata discipline, payload lifecycle management, and operational review.
Quick Answer
Large browser tool suites stay maintainable when independent tools share contracts for routing, registries, content, metadata, schema, validation, processing boundaries, and local execution behavior.
Execution Consistency Becomes Operational Debt
Each tool should solve one workflow clearly. That independence is useful. The risk appears when every tool also invents its own content shape, metadata path, image handling, related links, validation behavior, and runtime boundary.
Large suites need shared contracts for route structure, category mapping, content fields, schema, capability metadata, renderer behavior, worker cleanup, progress states, and payload handling. Without those contracts, every upgrade becomes a search for exceptions.
The debt becomes visible when two tools process similar files but behave differently under load. One releases preview URLs, one does not. One reports per-file errors, one fails the whole batch. One handles mobile memory pressure with a warning, one lets the tab freeze.

Registries Are Product Infrastructure
A registry is not just a list. It is how the platform knows what exists, where it belongs, and how it should be discovered. Duplicate slugs, vague labels, and inconsistent categories create downstream issues in navigation, internal linking, schema, and search reporting.
Registry discipline also protects analytics. If tool identity drifts, demand signals become harder to interpret. A platform cannot prioritize upgrades confidently when its product map is unstable.
Content Debt Creates Search Ambiguity
A working tool can still carry debt through generic content. If five pages describe themselves with the same broad phrasing, search engines and users get weak signals. The page may be technically correct while failing to explain workflow intent.
That is why SHRTX content needs operational specificity. A file-size tool should explain upload payload diagnostics. A bento layout tool should explain responsive interface composition. The content contract is part of the technical system.
Metadata drift is part of the same problem. If an article, schema image, social preview, and tool page describe different workflows, the page may still render correctly while sending unstable signals to users, crawlers, and internal maintainers.
Dependency Drift Is a Frontend Scaling Problem
Tool suites can accumulate parsing libraries, image codecs, UI helpers, and one-off dependencies quickly. Package count matters, but the larger issue is whether unrelated routes start paying for code they do not use.
A user opening JSON Formatter & Validator should not download image compression logic. A user opening Bento Grid Builder should not inherit PDF tooling. Bundle boundaries are maintenance boundaries.
Browser-native execution makes this sharper. A large codec, worker module, or WASM dependency should load at the feature boundary, not at the suite boundary. Route-level code splitting and dynamic imports also keep one tool's runtime assumptions from leaking into another.
Payload Lifecycles Drift Quietly
Reviewers should not manually catch every duplicate title, missing capability, invalid image path, or malformed content field. Repeatable issues belong in validation.
Useful checks include slug consistency, duplicate title detection, content capability validation, image filename guards, schema smoke checks, generated prose scans, and asset path validation. These checks keep small edits small because they catch drift before code review becomes archaeology.
Runtime behavior needs similar discipline. If local tools accept files, they should share expectations around progress, cancellation, object URL cleanup, per-file error reporting, and memory-sensitive batch handling. Otherwise every new tool becomes a small fork of the platform runtime.
function releasePreview(url: string | null) {
if (!url) return
URL.revokeObjectURL(url)
}
function finishBatch(previews: Array<string | null>) {
for (const url of previews) releasePreview(url)
}
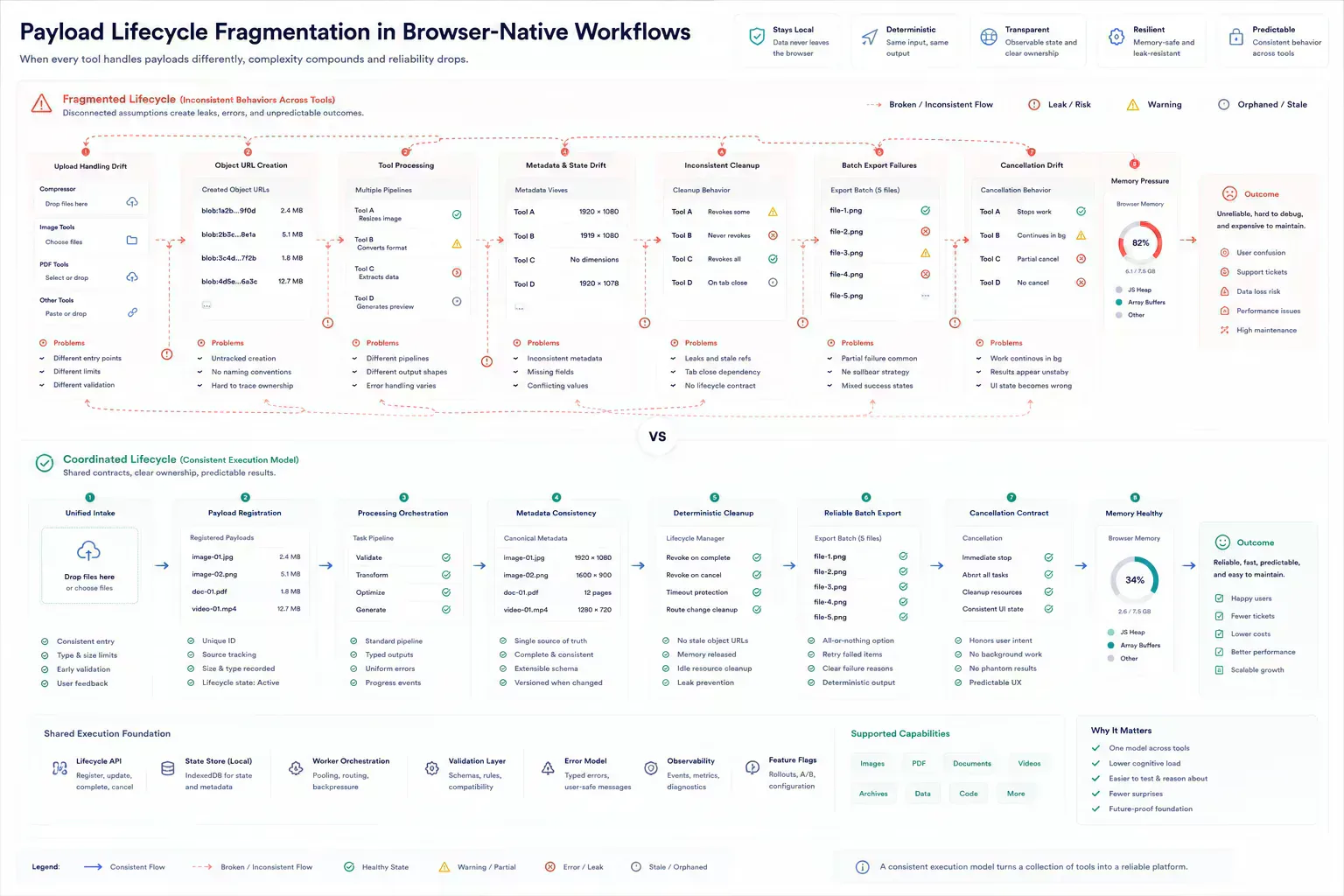
Browser Runtime Boundaries Need Shared Assumptions
A scalable suite treats every tool as independent, but not isolated. Add the registry entry, confirm slug and category alignment, define processing boundaries, write content in the shared structure, resolve metadata centrally, and link adjacent tools only where the workflow justifies it.
This creates enough structure to support hundreds of tools without turning every upgrade into a refactor. Variation remains possible, but it becomes intentional and auditable.
For browser-native tools, the processing boundary should be explicit. Is the work deterministic and local. Does it need network authority. Does it create blobs that require cleanup. Does it need a Worker, Streams, or transferable objects. Those answers are maintenance inputs, not implementation trivia.
| Shared Assumption | If Consistent | If Each Tool Invents It |
|---|---|---|
| Object URL cleanup | Memory behavior stays predictable | Large previews leak across sessions |
| Worker cancellation | Stopped tasks release compute promptly | Cancelled work keeps running in the background |
| Batch error reporting | Users can fix one failed file | One bad input destroys the whole workflow |
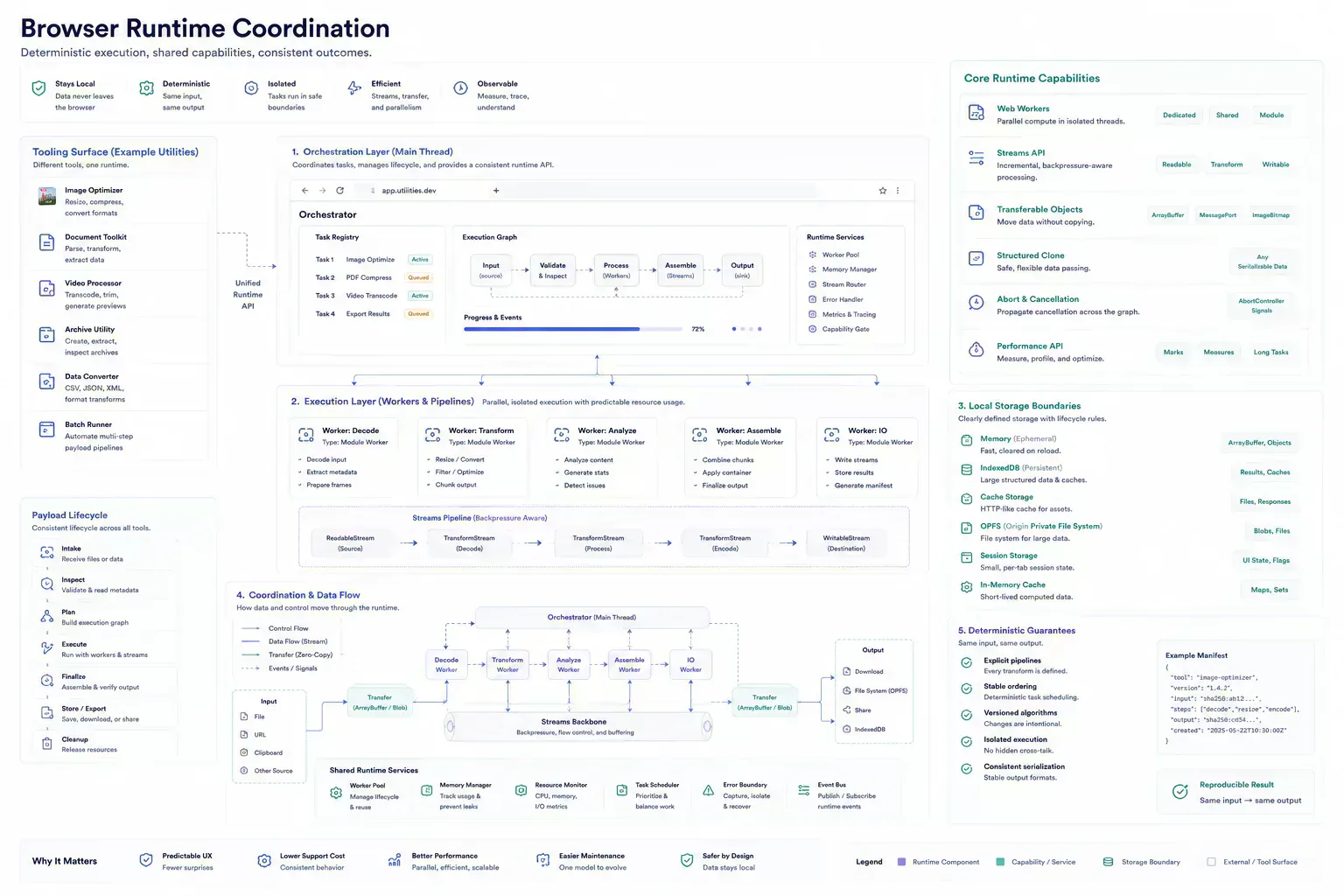
Where Teams Usually Lose Time
Technical debt in large browser tool suites is most relevant when a small issue reaches the wrong system. The route is crawled before redirects are clean. The image is uploaded before its dimensions are checked. The draft is distributed before tone or accessibility is reviewed. The payload reaches an API test before anyone validates the structure.
The cost extends beyond the fix. It is context loss. The person who finds the issue often has to reconstruct how the artifact was created, which constraint mattered, and which owner can still change it.
For engineering teams, the useful lens is runtime placement: what runs locally, what requires server authority, and what validation keeps shared contracts from drifting.
The same pattern appears inside the tools. A batch export fails because one file did not decode. A progress bar reaches 100 percent before ZIP generation finishes. A cancelled image task keeps processing in a worker. These are small inconsistencies, but they make the suite feel less reliable than the individual tools suggest.
Operational Continuity
A strong workflow keeps each step connected to the next decision. If the article discusses a file, the reader should understand the upload or sharing consequence. If it discusses frontend structure, the reader should understand the responsive or rendering consequence. If it discusses search, the reader should understand how crawlers and previews interpret the page.
Continuity is what separates workflow writing from broad advice. It lets the reader move from diagnosis to action without guessing the missing step.
For a browser-native ecosystem, continuity also means local audit flows should connect naturally. A payload check can lead to File Size Analyzer. Metadata uncertainty can lead to Image Metadata Viewer or EXIF Metadata Stripper. Public key inspection can stay local with PGP Key Viewer. The link is useful only when it continues the maintenance path.
Boundaries That Make the Advice Credible
Good operational guidance names limits. Browser-native processing is strong for local preparation, but it does not replace external verification, shared state, or regulated review. Automation catches repeatable drift, but human judgment still handles ambiguous meaning.
Those boundaries matter because they prevent the article from overpromising. The reader should leave with a clearer decision model, not a slogan.
The same restraint belongs in implementation. Local transforms are useful when the result is deterministic and user-scoped. Server systems still own shared truth, abuse controls, account state, and external verification. Technical debt grows when that boundary becomes implicit.
Handoff Discipline
The handoff is where many workflow problems become visible. A file reaches a CMS before its size is understood. A route is linked before redirect behavior is clean. A draft reaches distribution before the headline matches the article. A component enters a release before responsive behavior has been tested with real content.
The practical answer is not to add process everywhere. It is to add the right check before the artifact leaves the person who can still fix it quickly. That check should be small enough to run consistently and specific enough to catch a predictable failure.
In browser tools, that check often happens before upload or export. Confirm file size, inspect metadata, validate payload shape, then hand the artifact to the next system. Catching it later usually means someone has to reopen the original context.
Local-First Workflow Lens
A local-first lens does not mean every task must stay in the browser. It means the workflow should identify the point where local preparation is cheaper, safer, or clearer than remote processing. That point may be file inspection before upload, schema review before indexing, screenshot compression before publishing, JSON cleanup before API debugging, or headline review before distribution.
When the browser can provide the first useful answer, the workflow becomes easier to operate. The user can correct the artifact while context is still fresh. The team can avoid unnecessary retries. The platform can avoid receiving data it did not need.
The same lens keeps the guidance specific. It forces a boundary: before upload, before deployment, before indexing, before sharing, before publication, or before a remote system receives sensitive context. Once that boundary is clear, the article can stay useful without padding or keyword repetition.
It also keeps maintenance more predictable. A deterministic local transform should have deterministic cleanup, progress, cancellation, and export behavior across the suite.
Scaling Utility Ecosystems Requires Shared Runtime Expectations
Real workflows have device limits, platform limits, team handoffs, old assets, inconsistent samples, and deadlines. Good guidance should survive those constraints. It should not assume perfect data, perfect network conditions, or a team with unlimited time to inspect every artifact manually.
That is why small browser-native checks matter. They give teams a way to reduce uncertainty while the artifact is still close to the source. The result is not a perfect process. It is a more reliable path from local preparation to the next system.
The constraints are concrete. Mobile browsers degrade earlier. Large files expose memory cleanup mistakes. Export pipelines reveal mismatched assumptions about filenames, MIME types, and ZIP behavior. Technical debt often hides in those edges until the suite has enough tools for patterns to repeat.

What to Document
The useful documentation is short. Name the artifact, the destination, the check that was run, and the risk that remains. If a file was compressed, record that. If a redirect was verified, record the final destination. If a payload was cleaned, keep the representative sample. If a draft was adjusted for tone or accessibility, preserve the reason.
This creates continuity without turning the workflow into a report. The next person does not need to repeat the same diagnostic step, and the team has enough context to understand why the artifact is ready for the next system.
That context helps future maintenance because the reason for the check stays attached to the workflow rather than hidden in chat history. During redesigns, audits, migrations, metadata updates, image replacement passes, and tool upgrades, a short note can prevent the next maintainer from treating the page as detached from product behavior.
Content quality and operational maintenance meet in that record. The article preserves the reason for the workflow, and the tool ecosystem provides the check that keeps future updates practical.
Final Takeaway
Technical debt in browser tool suites is the accumulation of small contract violations. Some are visible in metadata or routing. Others sit inside runtime assumptions about compute placement, payload handling, worker lifecycle, cleanup, and export behavior.
The durable answer is not more process for its own sake. It is a set of shared boundaries that let independent tools remain coherent as one browser-native product system.
Tools Referenced By Topic
Related Reading
Jan 16, 2026 • 10 min
Scaling Browser Utility Suites Without Server Costs
A practical engineering guide to scaling browser-native utility suites with client-side processing, static deployment, local-first workflows, and lightweight infrastructure boundaries.
Mar 14, 2026 • 9 min
Leveraging Modern Web APIs for Desktop-Class Tools
Modern Web APIs let browser tools handle files, compute, and graphics with local speed and clear permissions, without installs.
Feb 13, 2026 • 12 min
The Local-First Software Movement: Building Web Apps That Run Directly on the User's Device
A practical engineering breakdown of local-first architecture, synchronization trade-offs, and privacy boundaries in modern web apps.